"A Continually LoRA PreTrained & FineTuned 7B Indic model"
LLMs are Artificial Neural Networks following the Transformer architecture. These Autoregressive Language Models work by using past input text values to repeatedly predict the next tokens. They can be used for tasks such as Natural Language Processing (NLP) and Machine Translation.Kannada (/ˈkɑ:nədə, ˈkæn-/; ಕನ್ನಡ), is a language spoken predominantly by the people of Karnataka in southwestern India, with minorities in all neighbouring states. It has around 44 million native speakers, and is additionally a second or third language for around 15 million non-native speakers in Karnataka.
As impactful these knowledge aggregators have become, their implementations come with inherent limitations such as their proprietary nature, computational resources required for training and deploying these models for inference, thus inhibiting the broader research community’s ability to build upon
their successes.
To tackle these, the Open Source community has gravitated towards Language Models with open weights and permissive licenses to build upon.
One of many such pivotal implementations was Meta's Llama 2 model released under permissive licenses for research and commercial usage, catapulting innovations in this space.
Despite these strides made by Llama 2, the model exhibits inherent limitations concerning native support for indic languages(Non English in general), as it was specifically trained on 2 Trillion English tokens, substantially hindering its ability to process non-English tokens.
We introduce - Kannada Llama, a small effort to expand Llama-2's existing linguistic capabilities for Low Resource Indic languages and specifically Kannada. We will release the models, code, datasets and the paper(eventually) under permissive licenses.
Tokenizer
A tokenizer is a tool that splits text into smaller units, called tokens. These tokens can be words, subwords, or even characters. This process is essential for a language model to analyze and generate text. Vocabulary in the context of a tokenizer, refers to the set of tokens that the tokenizer recognizes. Each token in this set is associated with a unique identifier.
The process starts with increasing the vocabulary. We increase Llama-2's existing vocabulary from 32K tokens to an aggregate
of 48k(49420) tokens to efficiently process kannada text.
We train a sentencepiece tokenizer with a vocab size of 20K on our kannada text corpus(used for pretraining also) and merge it with the existing Llama-2 tokenizer.
For the given piece of text, the difference between the 2 tokenizers is clearly visible:
ಎಂತಹ ಸುಂದರ ದಿನ! (what a beautiful day!)
Pre-Training
Low-Rank Adaptation (LoRA)LoRA achieves similar results to full fine-tuning by fine-tuning a smaller number of weights that approximate the larger weight matrix of the pre-trained model.
This fine-tuned adapter is loaded into the pre-trained model and used for inference, is created by this efficient training technique that preserves pre-trained model weights while incorporating trainable rank decomposition matrices. LoRA freezes the pre-trained model
weights and injects trainable low-rank matrices into each layer. This approach significantly reduces
total trainable parameters, enabling the training of LLMs with considerably fewer computational resources.
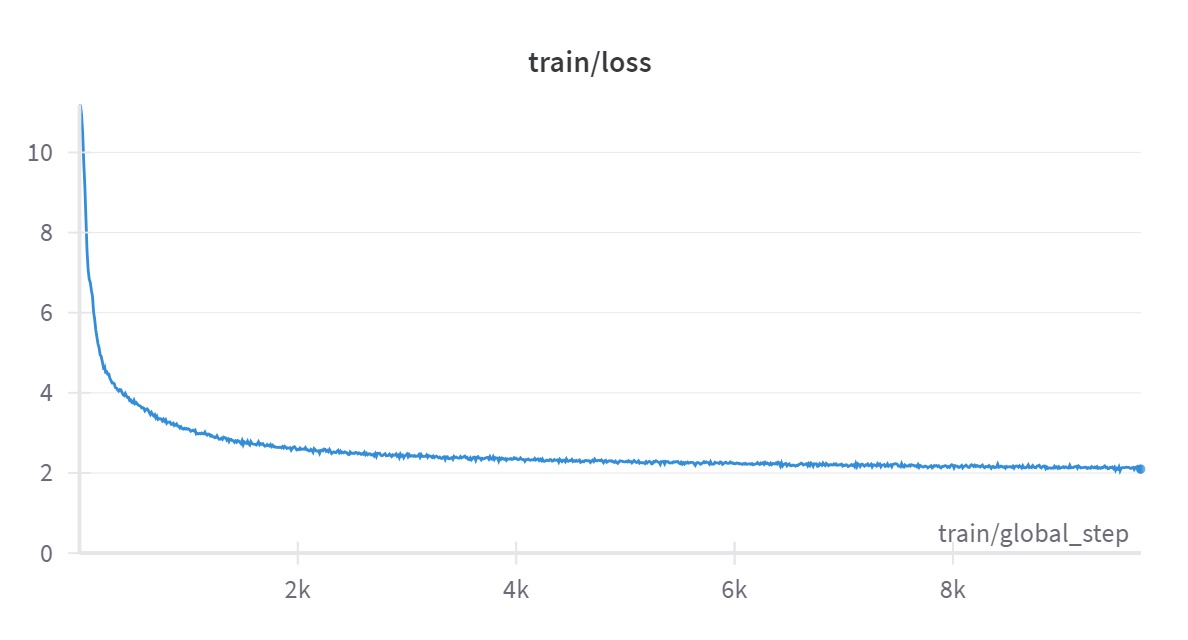
We Continually Pre Train Llama-2 on ~600 Million Kannada Tokens from the popular CulturaX Dataset. The dataset consists of multiple de-duplicated Multilingual dumps from popular scrapes such as mC4 and OSCAR. We randomly select documents from the same, resulting in a text corpus of ~11GB for pre-training step.
The Pre-Training was carried out on a single Nvidia A100 80GB instance and took ~50 hours with an approximate cost of $170. The resulting LoRA adapter was ~1.1GB in size.
PreTraining train/loss wandb logs
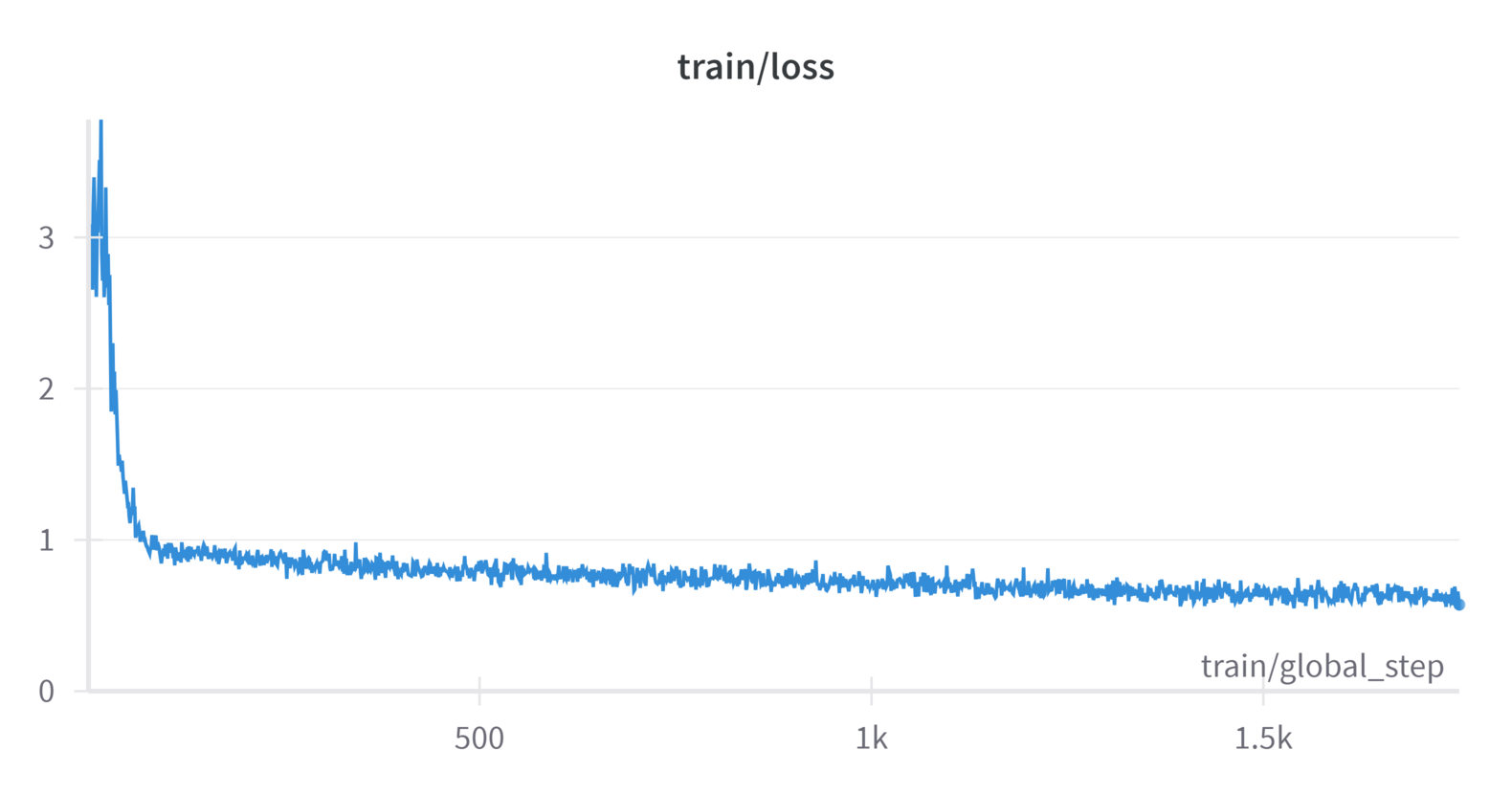
Fine-Tuning
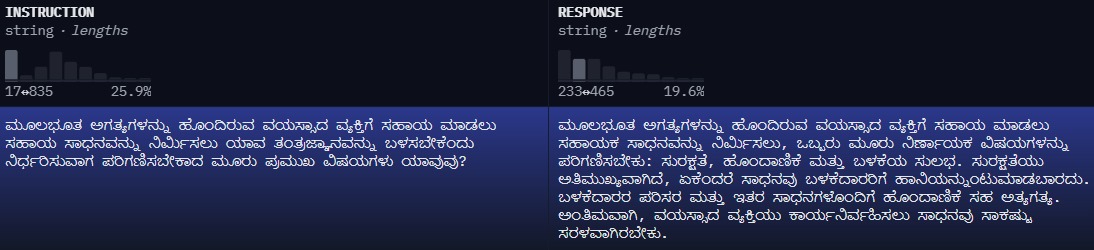
FineTuning is the process of training a pre-trained model on smaller, specific datasets to enhance its capabilities and adapt it to specialized tasks. We FineTune the hence obtained Kannada Base Llama on chat optimised and translated datasets for the ultimate
conversational capabilities.
The fine tuning datasets were curated manually. We release variants of the SFT version with the v0.1 under the cc-by-4.0 license(Since dataset used was of the same license) and the v0.2 under Apache 2.0 license.
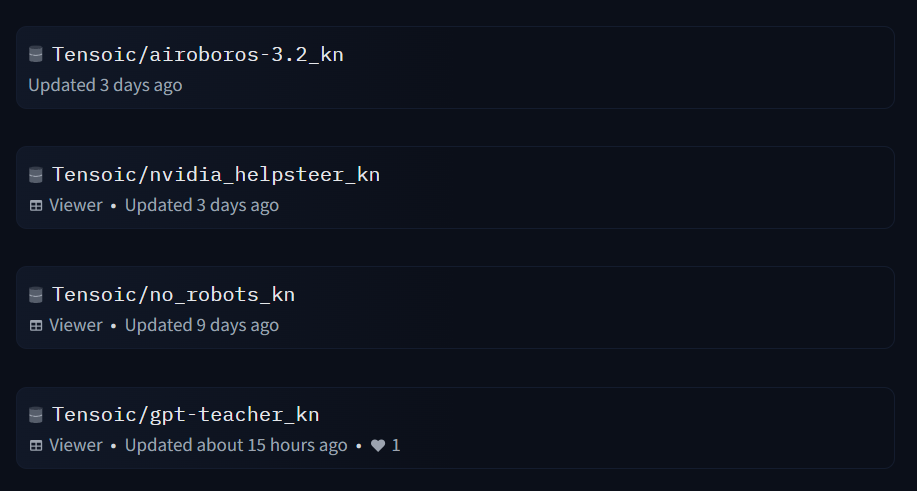
We also release the Fine Tuning datasets for further development through community contributions:
We use axolotl for the finetuning phase as it provides an easy yet powerful environment via YAML configs to FineTune LLMs. The configs used are/will be mentioned in the GitHub
Generation Examples
Here are some examples of Kannada Llama's generation capabilities.
The model used here is the quantised version: Q5_K_M.gguf
Find the models, dataset and collection:
Epilogue
We conclude with this, our small efforts to expand research to low resource Indic Languages and adapt Llama-2 to Kannada. We hope this will be a small step towards the larger goal of making LLMs more accessible to the broader research community and the public in general.
We will release the models, code, datasets and the paper(eventually) under permissive licenses.
We also thank Microsoft for their support in this endeavour with access to compute credits for the resource intensive(GPUs) training. We also look forward to collaborate with other research entities and accelerate the State of the Art!

 Kannada (/ˈkɑ:nədə, ˈkæn-/; ಕನ್ನಡ), is a language spoken predominantly by the people of Karnataka in southwestern India, with minorities in all neighbouring states. It has around 44 million native speakers, and is additionally a second or third language for around 15 million non-native speakers in Karnataka.
Kannada (/ˈkɑ:nədə, ˈkæn-/; ಕನ್ನಡ), is a language spoken predominantly by the people of Karnataka in southwestern India, with minorities in all neighbouring states. It has around 44 million native speakers, and is additionally a second or third language for around 15 million non-native speakers in Karnataka.